第三讲·Toffee 的安装与使用
掌握使用 Toffee 进行芯片验证的基本流程和关键技术,为后续独立完成验证任务打下基础
简介
在上一讲中,我们学习了如何使用 Picker 工具将 RTL 设计转换为可在高级语言(如 Python)中驱动的模块。虽然 Picker 提供了底层的硬件交互能力,但要构建一个结构化、可复用、易于维护的验证环境,还需要更完善的框架和方法学支持。
Toffee 正是为此而生。它是一个基于 Python 语言编写的硬件验证框架,构建于 Picker 之上,旨在提供一套更高效、更规范的验证解决方案。
Toffee 框架的主要功能特点包括:
标准化验证环境结构:借鉴了 UVM 等验证方法学的思想,提供了
Bundle(接口封装)、Agent(事务级驱动与监测)、Env(环境组织)、Model(参考模型)等核心组件,引导用户构建分层、模块化的验证平台。集成测试用例管理 (
toffee-test):通过与pytest框架集成,toffee-test插件简化了测试用例的编写、执行、管理和报告生成,支持fixture等高级测试特性。内建异步支持:核心基于 Python 的
asyncio协程,提供了async/await的原生支持和一系列异步等待机制(如AStep,ACondition),便于处理并发行为和精确的时序控制。功能覆盖率支持:内建
CovGroup,CovPoint,CovBin等类,支持方便地定义、收集和报告功能覆盖率,量化验证完备性。
相比直接使用 Picker,采用 Toffee 框架的优势:
更高的抽象层次:Toffee 将验证逻辑从底层的信号读写提升到事务级操作,使测试用例更关注于“测什么”而不是“怎么驱动信号”。
更强的结构化和规范性:提供了明确的验证环境组件和组织方式,提高了代码的可读性、可维护性和可复用性。
简化的测试流程:
toffee-test自动化了测试用例发现、执行和报告生成,集成了覆盖率收集,简化了整个验证流程的管理。方法学支持:融入了验证方法学的最佳实践(如驱动与监测分离、事务级建模、覆盖率驱动验证等),有助于新手建立规范的验证思维。
易于扩展和协作:模块化的设计使得验证环境更容易扩展,也更便于团队成员分工协作。
总而言之,Picker 解决了“如何用高级语言与硬件交互”的问题,而 Toffee 则在此基础上,提供了“如何高效、规范地用高级语言构建完整验证环境”的解决方案。本讲将详细介绍 Toffee 的安装和核心组件的使用方法。
1. Toffee 的安装
配置好 Python 环境后,可以通过以下命令安装 Toffee 及其测试工具 toffee-test:
pip3 install pytoffee@git+https://github.com/XS-MLVP/toffee@master
pip3 install toffee-test@git+https://github.com/XS-MLVP/toffee-test@master
❗关于
error: externally-managed-environment由于 PEP 668 的原因,如果出现该报错,建议使用 venv 创建一个虚拟环境,在虚拟环境中安装并使用 toffee
完成安装之后,我们可以尝试运行一段加法器的样例代码,来验证是否完成安装:
# 拉取代码
git clone https://github.com/XS-MLVP/toffee.git --depth=1
# 进入加法器示例的文件夹
cd toffee/example/adder
# 构建dut
make dut
# 运行测试
make run
如果配置成功,你会看到:
test_adder.py::test_random PASSED
test_adder.py::test_boundary PASSED
2. 使用 toffee-test 管理测试用例
在先前的环境中,我们需要手动管理测试用例。toffee-test 是 toffee 提供的一个 pytest 插件,用于管理 toffee 测试用例。
💡关于 pytest:Pytest 是 Python 中的一个软件测试框架。
它能够轻松编写简洁易读的测试用例,同时具备强大的扩展能力,足以支持应用程序和库的复杂功能测试需求。
Pytest 本身有强大的功能和丰富的生态,如果感兴趣的话,可以查阅 pytest 的文档和相关的插件仓库,来帮助你更好地完成验证任务。
在随机数生成器的例子中,仅使用 picker 的验证代码为:
from RandomGenerator import *
import random
# 定义参考模型
class LFSR_16:
def __init__(self, seed):
self.state = seed & ((1 << 16) - 1)
def Step(self):
new_bit = (self.state >> 15) ^ (self.state >> 14) & 1
self.state = ((self.state << 1) | new_bit ) & ((1 << 16) - 1)
if __name__ == "__main__":
dut = DUTRandomGenerator() # 创建DUT
dut.InitClock("clk") # 指定时钟引脚,初始化时钟
seed = random.randint(0, 2**16 - 1) # 生成随机种子
dut.seed.value = seed # 设置DUT种子
# reset DUT
dut.reset.value = 1 # reset 信号置1
dut.Step() # 推进一个时钟周期
dut.reset.value = 0 # reset 信号置0
dut.Step() # 推进一个时钟周期
ref = LFSR_16(seed) # 创建参考模型用于对比
for i in range(65536): # 循环65536次
dut.Step() # dut 推进一个时钟周期,生成随机数
ref.Step() # ref 推进一个时钟周期,生成随机数
rand = dut.random_number.value
assert rand == ref.state, "Mismatch" # 对比DUT和参考模型生成的随机数
print(f"Cycle {i}, DUT: {rand:x}, REF: {ref.state:x}") # 打印结果
# 完成测试
print("Test Passed")
dut.Finish() # Finish函数会完成波形、覆盖率等文件的写入
那么引入 toffee 和 toffee-test 之后,就可以通过 pytest 自动完成测试用例的运行和结果的收集。例如,在RandomGenerator.v所在的目录下创建 test_with_toffee.py:
# test_with_toffee.py
from RandomGenerator import DUTRandomGenerator
import random
import toffee_test
# 定义参考模型
class LFSR_16:
def __init__(self, seed):
self.state = seed & ((1 << 16) - 1)
def Step(self):
new_bit = (self.state >> 15) ^ (self.state >> 14) & 1
self.state = ((self.state << 1) | new_bit) & ((1 << 16) - 1)
@toffee_test.testcase
async def test_with_ref(dut: DUTRandomGenerator):
seed = random.randint(0, 2**16 - 1) # 生成随机种子
dut.seed.value = seed # 设置DUT种子
#### 初始化部分 ####
dut.reset.value = 1 # reset 信号置1
dut.Step() # 推进一个时钟周期
dut.reset.value = 0 # reset 信号置0
dut.Step() # 推进一个时钟周期
#### 初始化结束 ####
ref = LFSR_16(seed) # 创建参考模型用于对比
for i in range(65536): # 循环65536次
dut.Step() # dut 推进一个时钟周期,生成随机数
ref.Step() # ref 推进一个时钟周期,生成随机数
# 对比DUT和参考模型生成的随机数
rand = dut.random_number.value
assert rand == ref.state, "Mismatch"
@toffee_test.fixture
async def dut(toffee_request: toffee_test.ToffeeRequest):
# 使用toffee创建DUT并绑定时钟
rand_dut = toffee_request.create_dut(DUTRandomGenerator, "clk")
return rand_dut
随后运行:
pytest . -sv # . 代表命令行下当前的目录
# 如果想生成报告,执行
pytest . -sv --toffee-report
然后就可以看到 pytest 输出的测试结果,在当前目录下还会创建reports文件夹,里面包含了可视化的测试报告。
在只使用 picker 的代码中,我们需要把测试用例放在顶层代码环境中来手动控制运行;而引入 toffee 的代码,只要保证遵循 pytest 的规范,并添加装饰器@toffee_test.testcase,就可以由 pytest 管理并运行;此外,pytest 还有丰富的功能和各种插件,例如可以给测试用例添加 mark,来控制运行哪一类用例等。
2.1 Fixture
在正式执行测试用例之前,pytest 会先执行使用@toffee_test.fixture装饰器的函数。
fixture 是软件测试中的一个常用术语,在 pytest(以及 toffee-test)中,它指的是一种用于设置测试前置条件和管理测试资源的机制。Fixture 为测试用例提供了一个明确定义、可靠且一致的测试上下文。
通俗地讲,fixture 就像是测试的“脚手架”或“准备区”,它负责在每个需要它的测试用例运行之前,准备好所需的环境(如创建 DUT 对象、启动时钟、初始化 Agent 等),并在测试结束后进行可能的清理工作(如关闭文件、释放资源)。
使用 Fixture 的好处:
代码复用:将通用的设置逻辑(如创建 DUT)抽取到 Fixture 中,避免在每个测试用例中重复编写。
关注点分离:测试用例可以专注于测试逻辑本身,而将环境准备工作交给 Fixture。
资源管理:Fixture 可以确保资源(如 DUT 实例)在测试开始时被正确创建,并在测试结束后(如果需要)被清理。
依赖注入:Fixture 的返回值可以自动“注入”到需要它的测试用例的参数中。
在 toffee-test 中,定义 Fixture 需要遵循特定的规范:
@toffee_test.fixture # 1. 固定装饰器
async def dut(toffee_request: toffee_test.ToffeeRequest): # 2. 固定参数 toffee_request
# Fixture 的设置逻辑
...
rand_dut = toffee_request.create_dut(DUTRandomGenerator, "clk")
...
# 返回准备好的资源
return rand_dut # 3. 返回值将被注入测试用例
关键要素:
装饰器:必须使用
@toffee_test.fixture来声明这是一个 Toffee 测试的 Fixture。固定参数
toffee_request: Fixture 一定要包含一个名称为toffee_request(它的类型为toffee_test.ToffeeRequest) 的参数, 该参数也会提供一些实用的功能(如创建 DUTcreate_dut、添加覆盖组add_cov_groups);框架会自动传入这个对象。返回值:Fixture 函数通过
return来提供准备好的资源。
执行机制与依赖注入:
当一个测试用例(如 async def test_with_ref(dut: DUTRandomGenerator))声明了一个与某个 Fixture 函数同名的参数(这里是 dut)时,pytest/toffee-test 会自动执行以下操作:
查找 Fixture:找到名为
dut的 Fixture 函数。执行 Fixture:在运行测试用例之前,先调用
dut()这个 Fixture 函数。注入结果:将
dut()Fixture 函数的返回值(即创建并启动了时钟的DUTRandomGenerator实例)传递给测试用例test_with_ref的dut参数。
⚠️重要提示:默认情况下,每个测试用例都会获得由 Fixture 重新执行并返回的独立实例。这意味着
test_with_ref使用的dut实例与另一个测试用例test_another(dut)使用的dut实例是不同的对象,它们之间状态隔离,确保了测试的独立性。
下图展示了 Fixture 如何为多个测试用例提供独立的 DUT 实例:
+---------------------------+
| fixture: dut() |
| return: DUTRandomGenerator|
+---------------------------+
|
| 返回值
v
+--------------+
| DUT instance | 注意:fixture返回的结果并不是测试用例之间共享的,每个用例都会获得独立的实例
+--------------+
|
|
| +---------------------------------------------------+
| | @toffee_test.testcase |
+---->| async def test_with_ref(dut: DUTRandomGenerator): |
| | await dut.generate() |
| | ... |
| +---------------------------------------------------+
|
| +---------------------------------------------------+
| | @toffee_test.testcase |
+---->| async def test_another(dut: DUTRandomGenerator): |
| | result = await dut.get_random() |
| | ... |
| +---------------------------------------------------+
|
| +---------------------------------------------------+
| | @toffee_test.testcase |
+---->| async def test_third(dut: DUTRandomGenerator): |
| await dut.setup() |
| ... |
+---------------------------------------------------+
通过使用 Fixture,我们可以有效地组织测试环境的准备工作,让测试用例本身更简洁、更专注于验证逻辑。关于 Fixture 的作用域(如 session、module 级别共享),可以查阅 pytest 和 python 的相关文档。
2.2 测试用例的规范
一般来说,对于包含测试用例的文件,需要遵循:
定义为异步函数
包含测试用例的文件要以
test_为前缀或_test为后缀每个测试用例(即函数或方法)的名称,需要以
test为前缀,更具体的规则请参考 pytest 文档每个测试用例要有和 fixture 函数同名的参数,这样才能让 pytest 注入结果
随着验证代码量的增加,使用 toffee 和 toffee-test 能显著提升验证效率、优化验证的工作体验。
3. 使用异步环境
在之前 toffee-test 的示例代码中,我们注意到函数定义前都添加了 async 关键字。这是因为 Toffee 框架的核心是基于协程的异步编程模型协程函数。
硬件验证天然涉及大量并发活动和精确的时间同步。例如,我们需要同时驱动多个 DUT 接口,监测各种信号,等待特定的时钟边沿或事件发生,与参考模型进行交互等。如果使用传统的同步阻塞式编程(即一个函数调用必须等待其完全返回后才能执行下一步),代码会难以表达这种并发性,或者导致仿真效率低下(因为一个等待操作会阻塞所有其他活动)。虽然可以使用回调函数来处理异步事件,但这往往会导致控制流变得碎片化,容易陷入所谓的“回调地狱”,代码难以阅读和维护。
3.1 异步函数
我们首先需要了解两个 Python 关键字 async 和 await,它们是使用协程的基础。
async关键字
当我们在函数定义前加上 async 关键字时,这个函数就变成了一个协程函数(也称“异步函数”,下文统一使用“异步函数”):
async def my_coro():
...
但是直接调用异步函数(例如 my_coro())并不会立即执行其内部的代码。相反,它会立即返回一个协程对象。这个协程对象本质上像是一个“待执行的任务”或“执行计划”,包含了运行协程所需的信息,但它本身并不会自动运行。
await关键字
await 关键字只能在 async def 函数内部使用。它的作用是执行并等待一个协程对象完成。当我们在异步函数内部使用 await 关键字时,就可以执行一个异步函数,并等待其执行完成并返回结果:
import asyncio
async def my_coro():
return "my_coro"
async def my_coro2():
result = await my_coro()
"""
等价于:
coro_obj = my_coro()
result = await coro_obj
"""
print(result)
if __name__ == "__main__":
asyncio.run(my_coro2()) # 执行my_coro2()
在顶层的普通(非 async)代码中,需要使用像 asyncio.run(coro_object) 这样的机制来启动事件循环并执行协程对象。
注意:在后续使用
@toffee_test.testcase装饰的测试用例中,测试框架会自动处理事件循环的运行,通常无需手动调用asyncio.run。
3.2 实现并发
使用 async def 定义函数和 await 调用之所以能实现并发(或异步执行)效果,其核心机制在于事件循环和协程机制。
工作流程如下:
async def标记可暂停:async def标记的函数是一个协程,表明它内部可能包含耗时或需要等待的操作,并且它有能力在这些点暂停执行。await触发暂停与执行权让出:await关键字标志着协程中发生暂停的位置。当await一个无法立即完成的异步操作时(例如,后台I/O 操作、睡眠等待一定时间(sleep)或等待像硬件时钟推进这样的事件(dut.AStep(1)) ),当前协程会在此处暂停,并将执行权交还给事件循环,以便事件循环可以调度执行其他就绪的任务。需要注意的是,并非所有await都会导致立即的执行权切换;执行首先会进入被await的目标,只有当其内部遇到需要等待的阻塞操作时,才会发生实际的暂停和切换。事件循环接管调度:事件循环是后台的核心调度器。它回收执行权后,会检查其他协程任务并把已就绪(未处于等待状态)的任务调度到当前线程上运行。
切换到其他任务:事件循环选择一个就绪的协程并执行它。这个机制是模拟硬件并行行为的关键:在硬件仿真中,只有当“时钟推进”事件发生时,仿真时间才会前进,硬件的内部状态也随之更新。在此之前,所有软件操作都被视为在“零时间”内完成,从而可以在单个仿真时刻,为硬件准备好所有并行的输入。
事件完成与恢复:当某个被
await的异步操作最终完成时(例如时钟周期走完、信号变化),事件循环会收到通知,并将等待该事件的协程标记为可运行。在合适的时机,事件循环会恢复该协程的执行,使其从上次暂停的await语句之后继续。
总结来说:async def 定义了可暂停的单元,await 触发暂停和让出。事件循环利用协程让出的时间片运行其他任务,并在等待结束后唤醒原任务。这种基于等待点的快速任务切换,构成了协程实现并发的基础,使得多个任务能在单个线程上交错执行,看起来像在同时进行。
下面的示意图可以帮助理解这个切换过程:
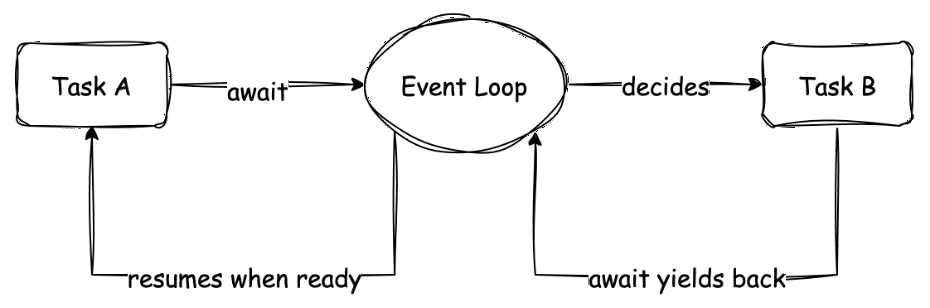
这张图展示了两个协程(任务 A 和 B)的执行流。从宏观上看,A 和 B 似乎是并行的。在微观上,当 A 需要等待事件时,它通过 await 让出控制权,事件循环(Event Loop)将执行权交给 B。当 B 也遇到等待时,可能又会切换回 A(若 A 的事件已完成)。这种协作式切换是协程并发的核心。
这种通过 await 实现的并发主要体现在单个任务流内部的等待与切换。对于需要启动多个独立运行、互不直接等待的后台任务(例如,同时运行多个独立的监测器或激励发生器),Toffee 还提供了其他机制来实现,我们将在后续内容中遇到(例如 toffee.create_task 或 Executor)。
3.3 管理 DUT 时钟
在传统的 Verilog 仿真或仅使用 Picker 的环境中,我们通过调用 dut.Step() 方法来手动推进时钟周期并更新 DUT 状态。然而,在需要精确控制等待特定时钟周期数或等待特定事件发生的异步验证场景中,仅仅依赖手动 Step() 是不够灵活的。我们需要一种机制来自动、持续地驱动时钟,同时允许我们的测试逻辑通过 await 来等待时间流逝。
Toffee 提供了 toffee.start_clock(dut) 函数来解决这个问题。当你调用 start_clock(dut) 时(通常在测试环境初始化阶段,如 Fixture 中),Toffee 会在后台启动一个专门负责驱动 dut 时钟信号(需要预先通过 create_dut 或 InitClock 指定时钟引脚)的任务。这个任务会根据仿真时间步进持续地翻转时钟信号,从而驱动整个设计的时序前进。
start_clock关键点
- 只能在异步函数里调用。
- 波形会额外多一个周期的结果,这个是为了后文提到的**监测方法(Monitor method)**刻意为之的。
引入 start_clock 管理时钟和异步等待方法后的代码示例如下:
from RandomGenerator import DUTRandomGenerator
import random
import toffee
import toffee_test
class LFSR_16:
def __init__(self, seed):
self.state = seed & ((1 << 16) - 1)
def Step(self):
new_bit = (self.state >> 15) ^ (self.state >> 14) & 1
self.state = ((self.state << 1) | new_bit) & ((1 << 16) - 1)
@toffee_test.testcase
async def test_with_ref(dut: DUTRandomGenerator):
seed = random.randint(0, 2**16 - 1)
dut.seed.value = seed
ref = LFSR_16(seed)
dut.reset.value = 1
await dut.AStep(1) # 等待时钟经过一个周期
dut.reset.value = 0
await dut.AStep(1) # 更新DUT状态
for i in range(65536):
await dut.AStep(1)
ref.Step()
assert dut.random_number.value == ref.state, "Mismatch"
@toffee_test.fixture
async def dut(toffee_request: toffee_test.ToffeeRequest):
rand_dut = toffee_request.create_dut(DUTRandomGenerator, "clk")
toffee.start_clock(rand_dut) # 让toffee驱动时钟,只能在异步函数中调用
return rand_dut
通过 start_clock 和 await AStep() 的配合,我们实现了测试逻辑与时钟推进的解耦,使得编写基于时间的异步验证序列更加自然和清晰。
3.4 其他的异步等待方法
除了 DUT 类提供的异步等待方法,toffee 也提供了一些实用方法,例如:
AllValid:等待传入的所有接口均为高电平Change:等待引脚信号发生改变Condition:等待条件为真Value:等待引脚信号变为指定的值……
完整的内容请查看 API 文档关于 toffee.triggers.module 的内容。
练习
本节的练习已经发布,请查阅【学习任务2: Toffee 部分】 1. 用 toffee-test 管理测试用例。
⚠️关于练习
本讲的内容比较多,可以在阅读文字教程的时候,每完成一部分的阅读就上手做一下练习~
4. 使用 Bundle 封装端口
以下内容来自:如何使用 Bundle
在复杂的芯片设计中,DUT 可能包含大量的输入输出端口。为了有效地管理这些端口并与验证环境的其他部分交互,我们需要一种封装机制。
Bundle 在 Toffee 验证环境中扮演着关键角色。它主要用于:
接口封装与抽象: 将 DUT 的一组相关端口(例如,一个总线接口的所有信号)封装在一起,形成一个逻辑单元。
解耦 Agent 与 DUT: 作为
Agent(下一节将介绍) 与 DUT 交互的中间层,Bundle使得Agent的编写可以独立于 DUT 具体的端口名称和层次结构,提高了验证组件的可重用性。结构化访问: 对 DUT 接口进行层次化划分,使访问特定端口更加清晰和方便。
4.1 一个简单的 Bundle 的定义
要定义一个 Bundle,需要自定义一个新类,并继承 toffee 中的 Bundle 类。下面是一个简单加法器接口的 Bundle 定义示例:
from toffee import Bundle, Signals
class AdderBundle(Bundle):
# Signals(N) 一次性定义 N 个同名信号,常用于定义一组信号
# 这里我们定义了 5 个信号:a, b, sum, cin, cout
a, b, sum, cin, cout = Signals(5)
在这个 AdderBundle 类中,我们定义了五个信号:a、b、sum、cin 和 cout。这些信号逻辑上对应加法器的两个输入 (a, b)、和输出 (sum)、进位输入 (cin) 和进位输出 (cout)。
定义完成后,可以实例化 AdderBundle 并访问其包含的信号:
from bundle.adder_bundle import AdderBundle
# 实例化 Bundle
adder_bundle = AdderBundle()
# 通过 '.' 运算符访问并赋值信号的 value 属性
adder_bundle.a.value = 1
adder_bundle.b.value = 2
adder_bundle.cin.value = 0
# 等待时钟推进一个周期,更新引脚信号
await self.adder_bundle.step()
# 读取信号值
print(adder_bundle.sum.value)
print(adder_bundle.cout.value)
⚠️警告:不推荐重写 Bundle 的构造方法 ,除非你对 Bundle 的代码实现非常熟悉!
4.2 将 DUT 绑定到 Bundle
仅仅创建 Bundle 实例并对其进行操作,还无法影响到实际的硬件设计 (DUT)。我们需要将 Bundle 与 DUT 的端口进行“绑定”,建立连接。
bind 方法用于将 Bundle 实例与一个 DUT 对象进行绑定。假设我们有一个名为 DUTAdder 的加法器 DUT 类实例 adder,其端口名称恰好与 AdderBundle 中定义的信号名称相同:
# 假设 DUTAdder 是代表加法器硬件设计的类
# adder = DUTAdder()
adder_bundle = AdderBundle()
# 将 adder_bundle 绑定到 adder 这个 DUT 实例
adder_bundle.bind(adder)
执行 bind(adder) 后,Toffee 会自动查找 adder 对象中与 adder_bundle 内定义的信号名称相同的端口,并将它们连接起来。此后,对 adder_bundle.a 的赋值操作就会实际驱动 adder 上的 a 端口。
4.3 处理端口名称不匹配的情况
在实际项目中,DUT 的端口命名往往与我们在 Bundle 中定义的理想名称不同。例如,DUT 可能遵循特定的命名规范,如添加前缀、后缀或使用不同的命名风格。Bundle 提供了多种灵活的绑定策略来处理这种情况。
注意: 以下的
from_prefix,from_regex,from_dict都是 类方法 (Class Methods),它们用于在调用bind之前 创建Bundle实例,并配置好该实例后续绑定时应遵循的名称匹配规则
通过前缀进行绑定
假设 DUT 端口名相比 Bundle 信号名,都增加了一个 io_ 前缀:
(Bundle -> DUT)
a -> io_a
b -> io_b
sum -> io_sum
cin -> io_cin
cout -> io_cout
我们可以使用 from_prefix 方法创建 Bundle 实例,并告知它在绑定时需要匹配带有 io_ 前缀的 DUT 端口:
# 创建 DUT
adder = DUTAdder()
# 创建 Bundle 实例时指定前缀匹配规则
adder_bundle = AdderBundle.from_prefix('io_')
# 进行绑定,此时会自动寻找 DUT 上 io_a, io_b 等端口
adder_bundle.bind(adder)
通过正则表达式进行绑定
有时,名称对应关系更复杂,例如包含方向信息:
(Bundle -> DUT)
a -> io_a_in
b -> io_b_in
sum -> io_sum_out
cin -> io_cin_in
cout -> io_cout_out
这种情况下,可以使用正则表达式来提取 Bundle 中定义的原始名称。通过 from_regex 方法创建 Bundle,并提供一个包含捕获组的正则表达式:
adder = DUTAdder()
# 正则表达式 r'io_(.*)_.*' 会捕获下划线之间的部分
adder_bundle = AdderBundle.from_regex(r'io_(.*)_.*')
adder_bundle.bind(adder)
绑定时,Toffee 会:
尝试用正则表达式
r'io_(.*)_.*'匹配 DUT 的每个端口名。如果匹配成功(例如
io_a_in),提取正则表达式中所有捕获组的内容(这里是a)。将捕获到的内容(
a)与Bundle中定义的信号名进行匹配。如果匹配成功,则将 DUT 端口
io_a_in绑定到Bundle信号a。
通过字典进行绑定
最直接的方式是提供一个明确的映射字典,指定 Bundle 信号名到 DUT 端口名的精确对应关系:
(Bundle -> DUT)
a -> a_in
b -> b_in
sum -> sum_out
cin -> cin_in
cout -> cout_out
使用 from_dict 方法创建 Bundle,并传入映射字典:
adder = DUTAdder()
adder_bundle = AdderBundle.from_dict({
'a': 'a_in',
'b': 'b_in',
'sum': 'sum_out',
'cin': 'cin_in',
'cout': 'cout_out'
})
adder_bundle.bind(adder)
bind 时将严格按照字典查找对应的 DUT 端口进行绑定。
4.4 创建子 Bundle
复杂的接口通常可以分解为若干子接口。Bundle 支持嵌套,允许将一个 Bundle 定义为另一个 Bundle 的成员(子 Bundle),从而构建层次化的接口描述。
from toffee import Bundle, Signal, Signals
class AdderBundle(Bundle):
a, b, sum, cin, cout = Signals(5)
class MultiplierBundle(Bundle):
a, b, product = Signals(3)
class ArithmeticBundle(Bundle):
# 自身包含的信号
selector = Signal()
# 将 AdderBundle 作为子 Bundle,命名为 adder
# 并指定其绑定时需要匹配以 'add_' 为前缀的 DUT 端口
adder = AdderBundle.from_prefix('add_')
# 将 MultiplierBundle 作为子 Bundle,命名为 multiplier
# 并指定其绑定时需要匹配以 'mul_' 为前缀的 DUT 端口
multiplier = MultiplierBundle.from_prefix('mul_')
在 ArithmeticBundle 中,我们定义了一个选择器信号 selector,并包含了 AdderBundle 和 MultiplierBundle 的实例,分别命名为 adder 和 multiplier。访问子 Bundle 中的信号使用 . 运算符:
arithmetic_bundle = ArithmeticBundle()
arithmetic_bundle.selector.value = 1
arithmetic_bundle.adder.a.value = 1 # 访问子 Bundle adder 的信号 a
arithmetic_bundle.adder.b.value = 2
arithmetic_bundle.multiplier.a.value = 3 # 访问子 Bundle multiplier 的信号 a
arithmetic_bundle.multiplier.b.value = 4
绑定行为: 当对顶层 Bundle (ArithmeticBundle) 进行 bind 操作时,其包含的子 Bundle 也会被递归地绑定到 DUT 上。子 Bundle 的名称匹配规则(如 from_prefix('add_'))会作用于经过父 Bundle 匹配规则处理后的名称空间。
例如,如果 ArithmeticBundle 本身是这样创建的:ArithmeticBundle.from_prefix('io_'),并且 DUT 上有一个端口叫 io_add_a:
顶层
ArithmeticBundle的from_prefix('io_')规则会将io_add_a暂时映射为add_a。然后,子
Bundleadder的from_prefix('add_')规则会作用于add_a,将其映射为a。最终,DUT 端口
io_add_a会被绑定到arithmetic_bundle.adder.a。
字典和正则表达式匹配方式同样会将它们处理(映射或捕获)后的名称传递给子 Bundle 进行进一步匹配。
4.5 Bundle 中的实用操作(节选)
信号访问与赋值
访问信号值
除了 . 运算符,也可以用 [] 运算符通过字符串名称访问信号:
adder_bundle = AdderBundle()
adder_bundle['a'].value = 1
同时赋值所有信号
可以通过 set_all 方法同时将所有输入信号更改为某个值。
adder_bundle.set_all(0)
信号赋值模式更改
Bundle 中支持通过 set_write_mode 来改变整个 Bundle 的赋值模式。
同时,Bundle 提供了设置的快捷方法:set_write_mode_as_imme, set_write_mode_as_rise 与 set_write_mode_as_fall,分别用于设置 Bundle 的赋值模式为立即赋值、上升沿赋值与下降沿赋值。
Bundle 默认的信号赋值模式为上升沿写模式(Rise)。
消息支持(字典操作)
默认消息类型赋值(assign)
可以通过 assign 方法用字典快速地为 Bundle 中的多个信号赋值:
adder_bundle.assign({
'a': 1,
'b': 2,
'cin': 0
})
使用 '*' 可以为字典中未明确指定的信号设置默认值:
adder_bundle.assign({
'*': 0,
'a': 1,
})
子 Bundle 的默认消息赋值支持
当 assign 的 multilevel=True 时,可以使用嵌套字典赋值:
arithmetic_bundle.assign({
'selector': 1,
'adder': {
'*': 0,
'cin': 0
},
'multiplier': {
'a': 3,
'b': 4
}
}, multilevel=True)
当 multilevel=False (默认) 时,使用 . 符号指定子 Bundle 信号:
arithmetic_bundle.assign({
'*': 0,
'selector': 1,
'adder.cin': 0,
'multiplier.a': 3,
'multiplier.b': 4
}, multilevel=False)
默认消息类型读取
as_dict 方法会将 Bundle 当前的信号值转换为字典。同样支持 multilevel 参数控制输出格式(嵌套字典或扁平字典):
> arithmetic_bundle.as_dict(multilevel=True) # 输出嵌套字典
{
'selector': 1,
'adder': {
'a': 0,
'b': 0,
'sum': 0,
'cin': 0,
'cout': 0
},
'multiplier': {
'a': 0,
'b': 0,
'product': 0
}
}
> arithmetic_bundle.as_dict(multilevel=False) # 输出扁平字
{
'selector': 1,
'adder.a': 0,
'adder.b': 0,
'adder.sum': 0,
'adder.cin': 0,
'adder.cout': 0,
'multiplier.a': 0,
'multiplier.b': 0,
'multiplier.product': 0
}
自定义消息类型
如果你有自定义的数据结构 (类) 想用于与 Bundle 交互:
赋值给 Bundle:
在自定义类中实现
as_dict()方法,返回一个字典,然后用bundle.assign(my_message.as_dict())在自定义类中实现
bundle_assign(self, bundle)方法,直接在该方法内完成对bundle信号的赋值。然后可以直接调用bundle.assign(my_message),Toffee 会自动调用bundle_assign。
class MyMessage:
def __init__(self):
self.a = 0
self.b = 0
self.cin = 0
def __bundle_assign__(self, bundle):
bundle.a.value = self.a
bundle.b.value = self.b
bundle.cin.value = self.cin
my_message = MyMessage()
adder_bundle.assign(my_message)
- 从 Bundle 读取值: 当需要将 Bundle 中的信号值转换为自定义消息结构时,可以在自定义类中实现一个类方法
from_bundle(cls, bundle),用于从bundle读取信号值并创建该类的实例。
class MyMessage:
def __init__(self):
self.a = 0
self.b = 0
self.cin = 0
@classmethod
def from_bundle(cls, bundle):
message = cls()
message.a = bundle.a.value
message.b = bundle.b.value
message.cin = bundle.cin.value
return message
my_message = MyMessage.from_bundle(adder_bundle)
异步支持
在 Bundle 中,为了方便的接收时钟信息,提供了 step 函数。当 Bundle 连接至 DUT 的任意一个信号时,step 函数会自动同步至 DUT 的时钟信号。
可以通过 step 函数来完成时钟周期的等待。
async def adder_process(adder_bundle):
adder_bundle.a.value = 1
adder_bundle.b.value = 2
adder_bundle.cin.value = 0
await adder_bundle.step()
print(adder_bundle.sum.value)
print(adder_bundle.cout.value)
class SomeExample(Bundle):
...
async def operation(value):
...
await self.step(1)
...
4.6 小结
Bundle 是 Toffee 中与 DUT 端口交互的基础。它提供了强大的封装、绑定和操作功能。熟练使用 Bundle 是构建健壮验证环境的第一步。更详细的功能请参考 Toffee 官方文档。
4.7 练习
本节的练习已经发布,请查阅【学习任务2: Toffee 部分】 2. 使用 Bundle 封装 DUT。
5. 使用 Agent 进一步封装
Bundle 解决了与 DUT 端口信号层面的交互问题,但直接在测试用例中操作 Bundle 信号仍然比较底层。Agent 在 Toffee 中提供了一个更高层次的抽象,它通常封装一个或多个 Bundle,并定义与这些接口相关的 事务级 (Transaction-Level) 操作。
Agent 的主要目标是:
抽象操作: 将底层的信号操作(如握手协议)封装成有意义的事务(如
read_transaction,write_data)。驱动与监测分离: 清晰地划分主动发起操作(驱动)和被动观察行为(监测)的逻辑。
简化测试用例: 使顶层验证代码更关注于测试场景和数据,而不是具体的信号时序。
通过 Agent 封装为函数之后,上层只需关注如何调用函数。
一个 Agent 通常由两类核心方法组成:
驱动方法 (Driver Method):主动向 DUT 发起操作,通过控制
Bundle信号实现。通常带有参数(输入数据/配置)和返回值(操作结果/读取的数据)。监测方法 (Monitor Method):被动地观察
Bundle信号,当满足特定条件时,捕获接口上的活动或状态,并可能生成表示该活动的事务对象或数据。
5.1 初始化 Agent
定义 Agent 需要创建一个继承自 Toffee Agent 基类的新类:
from toffee import Agent
class AdderAgent(Agent):
...
在 AdderAgent 类初始化时,需要外界传入该 Agent 需要驱动的 Bundle,例如:
adder_agent = AdderAgent(adder_bundle)
如果一个 Agent 需要操作多个 Bundle (例如 FIFO 的读写接口),可以重写构造函数,接收多个 Bundle,但需要将其中一个传递给 super().__init__中,因为这个 Bundle 主要用于让 Agent 能够使用 step() 方法与仿真时钟同步。
以先前练习的 SyncFIFO 为例:
from toffee.agent import Agent
class FIFOAgent(Agent):
def __init__(self, read_bundle, write_bundle):
# 将 read_bundle 传给父类以获取时钟
super().__init__(read_bundle)
# 保存两个 Bundle 实例
self.read = read_bundle
self.write = write_bundle
...
...
5.2 创建驱动方法
驱动方法是 Agent 中用于主动执行操作的异步函数 (async def)。它负责解析输入参数,按照特定时序操作 Bundle 信号,并可能返回操作结果。
必须使用
@driver_method()装饰器标记。通过
self.bundle(或保存的其他 Bundle 成员) 访问和操作信号。访问信号、控制时钟等操作使用内部定义的成员变量
访问信号用内部定义的 Bundle。
等待时钟周期可以用
await self.bundle.step()(或await self.monitor_step())。
可以通过
return语句返回操作结果。
下面是 AdderAgent 的一个简单驱动方法示例:
from toffee.agent import *
class AdderAgent(Agent):
@driver_method()
async def exec_add(self, a, b, cin):
"""执行一次加法操作"""
self.bundle.a.value = a
self.bundle.b.value = b
self.bundle.cin.value = cin
# 等待一个时钟周期
await self.monitor_step() # 等价 self.bundle.step()
# 读取并返回结果
return self.bundle.sum.value, self.bundle.cout.value
在验证代码中,可以像调用普通异步函数一样调用驱动方法:
adder_bundle = AdderBundle()
adder_agent = AdderAgent(adder_bundle)
sum, cout = await adder_agent.exec_add(1, 2, 0)
print(sum, cout)
提示: 使用
@driver_method装饰器标记的方法,除了执行我们定义的逻辑外,Toffee 框架还会自动进行一些额外处理,例如与参考模型 (Reference Model) 的交互和结果比对(这部分内容将在后续章节介绍)。
5.3 创建监测方法
监测方法用于被动地观察 Bundle 接口上的活动。它们也是异步函数 (async def),并由框架自动、周期性地调用。
必须使用
@monitor_method()装饰器标记。框架会在每个时钟周期的特定阶段(见后文时序部分)自动调用所有监测方法。
监测方法内部逻辑通常是检查
Bundle信号是否满足特定条件(例如,某个使能信号有效,或者握手完成)。关键: 如果监测方法在某次调用中认为一次有效的活动/事务被捕获,它应该 返回 代表该活动的数据(例如一个字典、一个自定义事务对象等)。如果返回值不为
None,框架会认为监测到了一个事件,并将返回值存入内部的消息队列。如果返回None,则表示本周期没有监测到目标事件。如果监测方法的执行逻辑需要跨越多个时钟周期(例如,等待一个完整的传输结束),框架会等待其完成后再进行下一次调用。
下面是一个简单的监测方法示例,用于监测加法器输出 sum 大于 0 的情况:
from toffee.agent import *
class AdderAgent(Agent):
@monitor_method()
async def monitor_sum(self):
# 检查条件
if self.bundle.sum.value > 0:
# 条件满足,返回 Bundle 的当前状态作为监测到的数据
# 使用 as_dict() 获取包含所有信号值的字典
return self.bundle.as_dict()
# 条件不满足,返回 None (或不返回任何东西)
这个 monitor_sum 方法会在每个周期被框架调用。如果 sum 大于 0,它会返回一个包含当时所有信号值的字典;否则返回 None。
如果想在每个周期都无条件地捕获 Bundle 状态,可以这样写:
@monitor_method()
async def monitor_always(self):
return self.bundle.as_dict(multilevel=False)
5.4 获取监测消息
被 @monitor_method 标记的方法自动运行时,其非 None 的返回值会被放入一个与该方法同名的内部消息队列。要在测试用例中获取这些被监测到的数据,需要执行以下步骤:
- 启动监测队列: 在测试开始前(通常在 fixture 中),为需要获取消息的监测方法启动队列,并指定队列大小:
adder_agent.start_monitor("monitor_sum", 10) # 指定消息队列的大小, 默认大小为 4
- 检查队列大小(可选操作): 可以使用
monitor_size("method_name")获取当前队列中消息的数量。
message_count = adder_agent.monitor_size("monitor_sum") # 获取消息队列中的消息数量
- 获取消息: 在测试用例中,调用与监测方法同名的
Agent方法来从队列中获取消息。这是一个异步操作,如果队列为空,它会等待直到有消息进入。
result = await adder_agent.monitor_sum()
监测方法同样也与参考模型相关联,框架会自动将监测到的数据与参考模型的预期进行比较(后续章节介绍)。
5.5 Agent 中的时序
Agent 中的驱动方法和监测方法遵循以下基本时序规则:
监测优先: 在每个时钟周期的开始阶段,框架会首先调用所有的 监测方法。只有当所有监测方法(在该周期的调用)都执行完毕后,驱动方法(如果在本周期被验证代码调用)才会被执行。
启动与结束: 驱动方法可以在第 0 个时钟周期就被调用。监测方法从第 1 个时钟周期的起始时刻开始被框架自动调用。在整个测试流程结束时,监测方法会被额外调用一次,以确保捕获最后一个周期的状态。
下面的示意图展示了执行 5 次单周期驱动方法 exec_add 的时序:
cycle 0 cycle 1 cycle 2 cycle 3 cycle 4 cycle 5
test start ---------+-----------------+-----------------+-----------------+-----------------+----------------- test end
| | | | |
+---------------+ +---------------+ +---------------+ +---------------+ +---------------+
| exec_add | | exec_add | | exec_add | | exec_add | | exec_add |
+---------------+ +---------------+ +---------------+ +---------------+ +---------------+
| +-------------+ | +-------------+ | +-------------+ | +-------------+ | +-------------+
| | monitor_sum | | | monitor_sum | | | monitor_sum | | | monitor_sum | | | monitor_sum |
| +-------------+ | +-------------+ | +-------------+ | +-------------+ | +-------------+
| | | | |
---------+-----------------+-----------------+-----------------+-----------------+-----------------
5.6 完整的 Agent 示例
结合驱动和监测方法,AdderAgent 的完整代码如下:
# 代码位于 https://github.com/XS-MLVP/toffee/blob/master/example/adder/env/agent.py
class AdderAgent(Agent):
@driver_method()
async def exec_add(self, a, b, cin):
self.bundle.a.value = a
self.bundle.b.value = b
self.bundle.cin.value = cin
await self.bundle.step()
return self.bundle.sum.value, self.bundle.cout.value
@monitor_method()
async def monitor_once(self):
return self.bundle.as_dict()
5.7 练习
本节的练习已经发布,请查阅【学习任务2: Toffee 部分】 3. 使用 Agent 进一步封装。
6. 同步 FIFO 规范阅读
需要大家去阅读同步 FIFO 的规范,具体看:
本节目标
本小节旨在帮助验证新人学习如何快速阅读和理解芯片或硬件设计规范文档,并从中提炼出验证工作的重点。通过以 SyncFIFO 模块为例,带领大家逐步掌握:
如何识别模块功能和用途
如何理解接口和信号含义
如何分析模块内部行为
如何提炼出关键验证点和边界条件
阅读顺序推荐:五步法
所谓的五步,实际上就是从五个维度去理解验证文档,这需要我们在阅读前就带上这五个问题,一个一个去文章中寻找答案。
这样,你就可以把文档的阅读理解转化成五个题目,以做题的方式去理解文档;当你确保自己能答对这几个题的时候,你对硬件的规范设计就能称得上了然于胸了。
1. 理解模块的作用和目的
模块是什么?它想要实现什么?
- 这一步的作用在于,让我们形成对模块的宏观认识。
具体怎么做?
规范文档的最前方一般都会有一个总述性的描写,你可以从中了解到待验证模块的故事背景,在同步 FIFO 的案例中,你可以对照到
描述这一小节,就描述了这一部分内容,显然,FIFO 是大家所熟知的数据结构,光是听到这个名字,就能让我们一下子建立起一种熟悉的亲切感。剩余的内容介绍中,你可以了解到它的大致功能,应用场景,规格,遵循同步还是异步操作,这部分内容,可能会进一步加深你对故事背景的认识,但如果反而让你产生陌生的情绪,也不用慌张,在后面的阅读中,你会找到你想要的答案,重要的是,我们至少已经在前一步树立起故事背景的认识。
需要注意的是,不是所有模块都像 FIFO 那样为我们所熟知,不需要做进一步说明。很多情况下,需要通过阅读背景介绍建立宏观的认识。
2. 弄清输入输出信号
- 输入输出信号都代表什么?输入输出信号之间的协同关系是什么?
- 接口是模块与外界沟通的唯一方式,理解接口就是理解了模块的行为。
具体怎么做?
接口信号主要分为三大类,输入信号,输出信号,控制信号(其实也属于输入信号,但功能特殊,此处专门列出),下面以 FIFO 中的端口说明为例,请你自己按照分类,去理解 FIFO 的端口含义:
控制信号:用于控制整个模块
时钟信号:
clkreset 信号:
rst_n
输入信号:
写入信号:
写入数据信号:
data_i写入控制信号:
we_i
读取信号:
- 读取控制信号:
re_i
- 读取控制信号:
输出信号:
读取数据信号:
data_o输出状态信号:
full_o,empty_o
💡提示:这种分类方式并不是必须的,你可以按照个人喜好去分,比如读写使能信号可以归类与控制信号中
在弄清楚每个输入输出信号的含义之后,接下来,我们还需要搞清楚输入输出信号之间的组合/协同关系:
在上面这个例子中,其实信号之间的协同关系也已经浮出水面了:
输入信号中的写入信号协同进行信号的写入
输入信号中的读取控制信号控制输出信号中的读取数据信号的读出
3. 理解模块内部逻辑
模块里面是怎么工作的?逻辑是啥?
- 上一步,我们了解了信号的外部如何交互,接下来,我们深入内部,了解模块内部到底做了什么?
具体怎么做?
从这里开始,我们就要具体地理解模块的内部逻辑了(参照 FIFO 的
功能描述),我们需要把内部行为提取出来,细化成一个具体的点。对于一个模块而言,其行为逻辑无非就是由顶层信号的模块控制,模块更新,模块读取这几部分组成,我们可以从这几个视角去提取:顶层信号的控制
- 复位:根据reset信号,使同步 FIFO中的内部信号复位
模块更新:
内部数据更新:通过写入操作向同步 FIFO中存储数据(对应功能描述的写入操作部分)
内部状态更新:由输入信号(包括控制信号)导致的内部状态信号更新,比如写入操作会导致计数器变更(对应功能描述的计数器部分)。读或者写会触发指针更新。
模块读取:
内部数据读取:通过读取操作从同步 FIFO中读取存储的数据(对应功能描述的读取操作部**)**
内部状态读取:通过计数器记录同步 FIFO中存储的数据容量(对应功能描述的计数器部**)**
4. 识别极端或边界行为
极限情况怎么办?模块能不能“撑住”?
- 当你完成前面三步时,已经可以比较好的理解模块的大致设计了,现在我们要专门考虑一些极端情况,或者说边界情况
具体怎么做?
这部分内容可能需要从功能点自行总结,但在
FIFO案例中,我们直接给出了边界条件这一节。常见的边界条件有以下类型:
数据边界:比如写入数据的最大最小值是否有效。
控制信号边界:比如 FIFO 满时继续写入,空时读取(这里的控制信号不是指前文提到的顶层控制信号,而是驱动某一个功能执行的控制信号 like:
re_iwe_i)交互边界:多个信号同时发生作用时,模块是否能正确执行?
we_i = 1 & re_i = 1时模块能否同时处理读写请求?(典型场景:同时读写的 FIFO)we_i = 1 & rst_n = 0时,写请求是否被忽略?
5. 整理验证目标,建立验证计划
将所理解的一切转化为可执行的验证任务:之前的四步已足以让你完全理解整个模块了,接下来这一步,要求我们在此基础上,思考怎么建立起一个大致的验证计划了,这就要求我们关注文档中更细节的内容。
具体怎么做?
这一步要做的,其实就是在功能点的基础上细分测试点,并给出相应的覆盖点了。
FIFO案例中,我们直接给出了功能点和测试点这一节,很值得参考。关于如何划分测试点,我们在第一讲有详细阐述。
需要注意的是,使用这五步法阅读规范的时候,并不一定是顺序执行的,很可能有时候需要并行执行,比如一开始看端口列表时,不能通过字面上的意思理解端口的含义,而读完功能点时,才能回过头去理解。
7. 收集功能覆盖率
“If you can’t measure it, you can’t improve it.” — Peter Drucker (如果你无法衡量它,你就无法改进它。)
在芯片验证中,仅仅运行测试用例并通过(即没有 assert 失败)是远远不够的。“跑通了测试”并不意味着设计中不存在 Bug。我们需要一种方法来量化验证的进展和完备性。覆盖率就是用于此目的的关键指标。
前面章节已经涉及了代码覆盖率 ,例如行覆盖率、分支覆盖率、状态机覆盖率等。代码覆盖率衡量的是设计的源代码(RTL 代码)在仿真过程中有多少比例被执行到。它非常有助于发现设计中那些从未被任何测试触达的部分(所谓的“死代码”或测试激励无法到达的区域)。
然而,100% 的代码覆盖率 不等于 100% 的功能验证。想象一个简单的加法器,它的所有代码行都可能在测试中被执行过,但我们可能从未测试过两个负数相加的情况,或者从未触发过加法溢出的场景。这些关键的功能点或边界条件,代码覆盖率是无法直接体现的。
功能覆盖率正是弥补了这一不足。它衡量的是设计规格中定义的功能点、操作模式、关键参数组合、状态转换、边界条件等,是否在验证过程中被实际观察到或经历过。功能覆盖率直接关联验证计划 ,旨在回答核心问题:“我们计划要验证的所有功能和场景,是否真的都被测试覆盖到了?”
7.1 功能覆盖率模型
在深入了解其构成要素之前,我们先定义什么是功能覆盖率模型。
功能覆盖率模型是实现验证计划中测试点覆盖的具体代码实现。它不是一个抽象的概念,而是你在验证环境(例如使用 Toffee 框架)中编写的一组代码结构,其目的是:
定义“感兴趣”的事件: 明确规定需要监控哪些设计行为、哪些信号值或值的组合、哪些状态转换是重要的,这些都源于设计规格和验证计划。
监控仿真活动: 在仿真运行时,模型会持续观察 DUT 的行为和状态。
记录覆盖情况: 当模型定义的“感兴趣”的事件发生时,模型会记录下来(通常是标记对应的“覆盖区间/仓”被命中)。
量化功能的验证进度: 通过统计有多少预定义的事件被观察到,来衡量验证对设计功能的覆盖程度。
简单来说,功能覆盖率模型就像一个在仿真过程中动态执行的、基于功能需求的检查清单。这份清单由验证工程师根据设计规格编写,用于确认所有关心的功能场景是否都已在测试中出现。在 Toffee 中,这份“清单”就是由接下来要介绍的 CovGroup、CovPoint 和 CovBin 等元素构建而成的。
7.2 功能覆盖率的组成
在 Toffee (以及 SystemVerilog 等语言) 中,收集功能覆盖率通常涉及以下核心元素:
覆盖组 (
CovGroup): 一个逻辑容器,用于组织一组相关的覆盖项。通常对应验证计划中的一个高层功能点(例如,“FIFO 基本读写操作”)或一个接口。覆盖点 (
CovPoint): 定义在CovGroup内部,用于监视设计的某个特定行为、变量值或一组变量值的组合。它明确了我们要测量什么(例如,“FIFO 计数器的值”、“写操作时的状态”)。覆盖区间/仓 (
CovBin): 定义在CovPoint内部,代表了该覆盖点需要覆盖的具体数值、数值范围、状态转换或条件。它明确了覆盖点期望达到的具体状态。当某个 Bin 所定义的条件在仿真中被观察到时,该 Bin 就被认为“覆盖”了。
目标: 功能验证的目标通常是让功能覆盖率达到 100%,即所有在覆盖模型中定义的 CovBin 都至少被命中一次。任何未被覆盖的 Bin 都指示了验证的“盲点”,提示我们需要补充新的测试用例或调整现有的激励生成策略来覆盖这些缺失的场景。
7.3 构建功能覆盖率模型:基本原则
开发功能覆盖率模型不是一次性的任务,而是一个需要仔细规划和迭代完善的过程。它紧密依赖于对设计规格的理解和验证计划的制定。以下是一些关键原则:
1. 基于功能需求和验证计划
功能覆盖率模型必须源于设计规格和验证计划。验证计划中列出的每一个需要验证的功能点、特性、状态或场景,都应该在覆盖率模型中有对应的 CovGroup 或 Coverpoint 来衡量其覆盖情况。这确保了验证工作始终聚焦于设计的预期功能。
2. 基于观察数据
验证环境通常可以分为:
激励/控制路径: 负责产生输入信号,驱动 DUT。
响应/分析路径: 负责观察 DUT 的输出信号,检查其行为,并进行数据分析。
功能覆盖率的收集点应该位于分析路径。也就是说,覆盖率模型应该采样和记录 DUT 实际表现出的行为和状态(通常通过监测接口的 Agent 或 Monitor 获取),而不是采样激励端发送给 DUT 的数据。
原因: 如果基于激励端采样,当 DUT 或激励本身存在问题时(例如,DUT 没有正确响应激励,或者激励发送了错误的数据),覆盖率数据可能会产生误导,报告某个功能已被“覆盖”,而实际上 DUT 并未按预期执行该功能。基于对 DUT 实际输出的观察来采样,才能确保覆盖率反映的是真实的设计行为。
所以,在搭建验证环境时,功能覆盖率需通过分析事务的内容来构建。这对验证环境和分析事务的设计提出了以下要求:
观测与激励分离:覆盖率模型需独立于激励生成逻辑,仅依赖 DUT 的实际输出。
分析事务的完整性:需确保事务数据完整记录 DUT 的响应状态(如信号值、时序等)。
覆盖率驱动的验证:工程师需要通过分析已有的覆盖率数据,指导后续激励生成。
3. 面向分析而设计
功能覆盖率报告是给验证工程师看的。一个设计良好的覆盖率模型不仅能准确衡量覆盖情况,还应该易于理解和分析。当出现覆盖漏洞时,工程师需要能快速定位到是哪个功能点的哪种具体情况没有被覆盖到。
清晰命名: 为
CovGroup、Coverpoint和Bin使用描述性强、易于理解的名称。例如,fifo_state_covgroup,counter_value_cp,bin counter_is_zero。合理组织: 将相关的覆盖点组织在同一个
CovGroup中。利用语言特性: 使用 Toffee 提供的功能(如 Bin 的命名等)来提高报告的可读性。
在模型设计阶段投入时间优化其结构和命名,可以在后续分析覆盖率报告时节省大量时间。
4. 确定适当的详细程度
需要权衡覆盖率模型与设计实现的匹配精度以及抽象的程度:
匹配精度: 模型需要多详细地反映设计的内部状态或接口信号?
抽象层级: 可以在多大程度上对细节进行抽象或简化?
例如,对于一个 32 位的地址总线,为每个可能的地址值创建一个 Bin 是不现实的。更合适的做法是定义一些关键的 Bin,比如说:
边界值:地址 0,地址最大值。
特定区域:某个内存区域的起始和结束地址范围。
对齐方式:检查奇偶地址访问。
一些随机采样值。 这就需要进行抽象,将无限的可能性归纳为有限的、有代表性的覆盖目标。
对于配置寄存器中的几个标志位,可能就需要覆盖它们所有 $2^N$ 种组合。
5. 覆盖点和覆盖仓的关键考量
在定义覆盖点和覆盖仓时,需要思考:
哪些值是重要的?
识别出设计规格中要求的、或可能引发特殊行为的关键值、状态或模式。
例如:FIFO 的空、满、半满状态;特定的操作码;错误标志位。
是否存在边界条件?
关注数值范围的边界(最小值、最大值、零值)、状态转换的临界点、协议时序的极限情况。
例如:计数器溢出前后;缓冲区刚好满/空;定时器超时。
数据之间是否存在依赖关系?
如果多个信号或变量的状态组合起来才有意义,或者它们的组合会影响设计行为,就需要定义交叉覆盖 (Cross Coverage)。
例如:覆盖读操作 (
re_i=1) 发生在 FIFO 非空 (empty_o=0) 的情况;覆盖特定的配置位组合。
是否存在非法或不期望的条件?
可以定义
illegal_bins来捕获那些根据设计规格不应该发生的状态或组合。如果illegal_bin被命中,通常表示存在设计错误或验证环境错误。例如:FIFO 同时报告满 (
full_o=1) 和空 (empty_o=1)。
是否存在需要忽略或不关心的条件?
可以使用
ignore_bins来排除那些虽然可能发生、但对当前验证目标不重要或无效的条件。例如:在复位期间的信号值;某些交叉覆盖中逻辑上不可能的组合。
优先级和分阶段目标:
并非所有覆盖点都同等重要。
根据验证计划,为覆盖点设定优先级。优先确保 P1 级别的覆盖点达到 100%,再逐步关注 P2、P3。
6. 确定正确的参样时机
选择正确的采样时刻至关重要,错误的采样可能导致覆盖率数据无效或遗漏。采样点需要满足:
相关检查已通过 (可选但推荐): 最好在确认 DUT 的行为是正确的之后再采样覆盖率,以避免记录错误行为下的覆盖。
数据有效 (Data Valid): 确保在采样时刻,所关心的信号值是稳定且有意义的。例如,在总线协议中,通常在握手信号确认传输完成的那个周期进行采样。
数据稳定 (Data Stable): 避免在信号正在跳变的时刻采样。
7. 确定采样结果是有效的
需要考虑在哪些情况下,即使满足了采样条件,该次采样也应该被视为无效或应被特殊处理。例如:
DUT 正处于复位状态。
刚刚更改了操作模式,需要等待几个周期让状态稳定。
正在进行错误注入测试,此时的覆盖率可能需要与正常操作的覆盖率分开统计。
可以通过在采样逻辑中添加额外的判断条件来处理这些情况。
7.4 在 Toffee 中收集功能覆盖率
Toffee 通过 toffee.funcov 模块提供功能覆盖率相关的类和方法。
定义覆盖组 (CovGroup) 和覆盖点 (add_watch_point)
- 创建覆盖组:
from toffee.funcov import CovGroup
from agent.fifo_agent import FIFOAgent # 假设已有 FIFOAgent
def get_cover_group_fifo_state(agent: FIFOAgent) -> CovGroup:
# 创建一个名为 "FIFO state" 的覆盖组
group = CovGroup("FIFO state")
# ... 在这里添加覆盖点 ...
return group
添加覆盖点: 使用 group.add_watch_point() 方法。该方法需要:
监视对象: 要监视的信号或
Bundle实例 (例如agent.internal.counter,agent.write,agent.internal)。Bins 字典: 一个字典,定义了该覆盖点的所有 Bins。
Key: Bin 的名称 (字符串)。
Value: 定义该 Bin 命中条件的逻辑。可以是:
比较函数: 如
CovEq(1),CovIsInRange(7, 9)等,用于检查监视对象的值。检查函数: 一个函数 (普通函数或 lambda),接收监视对象作为参数,返回
True(命中) 或False(未命中)。
name参数: 覆盖点的名称,用于报告。
编写技巧
检查单个信号的值
使用 toffee.funcov 提供的比较函数很方便:CovEq, CovGt, CovLt, CovGe, CovLe, CovNe, CovIn, CovNotIn, CovIsInRange。例如,如果我们想检测同步 FIFO 中counter的取值情况:
def get_cover_group_fifo_state(agent: FIFOAgent) -> CovGroup:
# Create coverage group
group = CovGroup("FIFO state")
# Add coverage points
...
# 检测counter信号
group.add_watch_point(agent.internal.counter, {
"one": CovEq(1),
"middle": CovIsInRange(7, 9), # counter的值在 7~9 之间
"near_full": CovIsInRange(14, 15),
}, name="counter")
return group
检查涉及多个信号的条件
当 Bin 的条件涉及多个信号或更复杂的逻辑时,需要提供一个检查函数。
Lambda 表达式
对于简单的条件,最直接的写法是使用 Lambda 表达式。
命名函数
更推荐使用命名函数,不仅会有更好的维护性,而且在编码时还会方便 IDE 提供补全支持:
from toffee.funcov import CovGroup
from agent.fifo_agent import FIFOAgent
from bundle.fifo_bundle import WriteBundle, ReadBundle
# --- 定义检查函数 ---
def check_write_operation(bundle: WriteBundle) -> bool:
return bundle.we_i.value and not bundle.is_full()
def check_read_operation(bundle: ReadBundle) -> bool:
return bundle.re_i.value and not bundle.is_empty()
def check_none_operation(agent: FIFOAgent) -> bool:
return not agent.read.re_i.value and not agent.write.we_i.value
# --- 创建覆盖组 ---
def get_cover_group_basic_operations(agent: FIFOAgent) -> CovGroup:
group = CovGroup("Basic operations")
# --- 添加覆盖点,使用命名函数 ---
group.add_watch_point(agent.write, {"write_occurs": check_write_operation}, name="Write operation")
group.add_watch_point(agent.read, {"read_occurs": check_read_operation}, name="Read operation")
group.add_watch_point(agent, {"no_operation": check_none_operation}, name="No operation")
return group
处理规律性强的条件 (工厂函数)
当多个 Bins 的检查逻辑相似,只有少量参数不同,可以使用“工厂函数”模式来生成检查函数。例如,读写指针只有三种比较关系:等于、大于、小于,检查函数可以定义为:
def wptr_compare_rptr(compare_type: int):
def compare(bundle: InternalBundle) -> bool:
if compare_type == 0:
return bundle.wptr.value == bundle.rptr.value
elif compare_type == 1:
return bundle.wptr.value > bundle.rptr.value
else:
return bundle.wptr.value < bundle.rptr.value
return compare
创建检查函数的时候,传入wptr_compare_rptr(0)、wptr_compare_rptr(1)、wptr_compare_rptr(2)就得到了三种情况的函数对象compare,我们就可以通过一个字典表达式完成对三种指针情况收集的编码:
def get_cover_group_pointer_compare(agent: FIFOAgent) -> CovGroup:
# Define coverage conditions
def wptr_compare_rptr(compare_type: int):
def compare(bundle: InternalBundle) -> bool:
if compare_type == 0:
return bundle.wptr.value == bundle.rptr.value
elif compare_type == 1:
return bundle.wptr.value > bundle.rptr.value
else:
return bundle.wptr.value < bundle.rptr.value
return compare
# Create coverage group
group = CovGroup("Pointer compare")
# Add coverage points
names = ["equal", "greater", "less"]
"""
下面的代码等价于:
group.add_watch_point(agent.internal, {
"equal": wptr_compare_rptr(0),
"greater": wptr_compare_rptr(1),
"less": wptr_compare_rptr(2),
}, name="Compare wptr with rptr")
"""
group.add_watch_point(agent.internal, {
names[i]: wptr_compare_rptr(i) for i in range(3)
}, name="Compare wptr with rptr")
return group
后续还想进一步扩充情况,不仅要维护wptr_compare_rptr,还要维护names中每种情况对应的名字,可以考虑引入 Python 中的枚举类 Enum:
# Enum需要导入
from enum import Enum, auto
class Compare(Enum):
Equal = auto()
WptrAhead = auto()
RptrAhead = auto()
我们就可以通过Compare类的__members__.items()方法,得到每种情况的名字和对应的值:
for name, value in Compare.__members__.items():
print(name, value)
# 输出
Equal Compare.Equal
WptrAhead Compare.WptrAhead
RptrAhead Compare.RptrAhead
完整的代码就变成:
def get_cover_group_pointer_comparefuck(agent: FIFOAgent) -> CovGroup:
class Compare(Enum):
Equal = auto()
WptrAhead = auto()
RptrAhead = auto()
# Define coverage conditions
def wptr_compare_rptr(compare_type: Compare):
def compare(bundle: InternalBundle) -> bool:
if compare_type is Compare.Equal:
return bundle.wptr.value == bundle.rptr.value
elif compare_type is Compare.WptrAhead:
return bundle.wptr.value > bundle.rptr.value
else:
return bundle.wptr.value < bundle.rptr.value
return compare
# Create coverage group
group = CovGroup("Pointer compare")
# Add coverage points
group.add_watch_point(agent.internal, {
name: wptr_compare_rptr(compare) for name, compare in Compare.__members__.items()
}, name="Compare wptr with rptr")
return group
如果你使用的 Python 版本≥ 3.11,还可以使用match... case语句来编写wptr_compare_rptr,抛弃繁琐的if... elif... else...结构:
# Version of python >= 3.11
def wptr_compare_rptr(compare_type: Compare):
def compare(bundle: InternalBundle) -> bool:
match compare_type:
case Compare.Equal:
return bundle.wptr.value == bundle.rptr.value
case Compare.WptrAhead:
return bundle.wptr.value > bundle.rptr.value
case Compare.RptrAhead:
return bundle.wptr.value < bundle.rptr.value
case _:
return False
return compare
覆盖率数据的收集与采样
定义好 CovGroup 之后,需要在仿真过程中适时地调用其 sample() 方法来采集数据,判断哪些 Bins 被命中。
时钟上升沿采样
最常见的方式是在每个时钟周期的固定上升沿,对所有需要周期性检查的覆盖组进行采样。toffee-test 提供了便捷的机制来实现这一点:
在测试的 fixture (例如
agentfixture) 中,实例化所有需要周期性采样的CovGroup对象。将这些
CovGroup对象放入一个列表。调用
toffee_request.add_cov_groups(your_group_list)。
add_cov_groups 会自动完成以下工作:
注册列表中的每个
CovGroup,使其sample()方法在每个时钟上升沿被自动调用。在测试结束时,自动将这些
CovGroup的覆盖率统计结果导出到报告中。
以下面代码为例,每个测试函数传入的是一个 agent 对象:
@toffee_test.fixture
async def agent(toffee_request: toffee_test.ToffeeRequest):
# Creat DUT
fifo_dut: DUTSyncFIFO = toffee_request.create_dut(DUTSyncFIFO, "clk")
# Start clock
start_clock(fifo_dut)
# Create bundles
read = ReadBundle().bind(fifo_dut)
write = WriteBundle().bind(fifo_dut)
internal = InternalBundle().from_prefix("SyncFIFO_").bind(fifo_dut)
# Create agent
fifo_agent = FIFOAgent(fifo_dut.rst_n, read, write, internal)
# 自动在时钟上升沿注册、收集覆盖率信息
toffee_request.add_cov_groups([
get_cover_group_basic_operations(fifo_agent),
get_cover_group_fifo_state(fifo_agent),
get_cover_group_boundary_operations(fifo_agent),
get_cover_group_pointer_compare(fifo_agent)
])
return fifo_agent
基于特定时序或条件的采样
有些覆盖点需要在满足特定时序序列或复杂条件后才进行采样,而不是每个时钟周期都采样。例如,FIFO 指针回绕 (wraparound) 的覆盖,需要在指针先达到最大值 0xf,然后变为 0 的那一刻才采样。
对于这种情况,不能使用 add_cov_groups 的自动采样。需要:
手动实例化
CovGroup,但不添加到add_cov_groups的列表中。编写异步任务 (
async def函数),该任务负责监测触发采样的序列或条件。在异步任务内部,当序列或条件满足时,手动调用
your_group.sample()。启动异步任务:使用
toffee.create_task()来启动这个监测任务,让它在后台独立运行。确保覆盖率结果被导出: 由于该
CovGroup未通过add_cov_groups注册,测试框架默认不会导出其结果。需要在 fixture 的yield之后 (即测试函数执行完毕后),手动将这个CovGroup对象添加到toffee_request.cov_groups列表中。
yield 在 fixture 中的作用
当 fixture 使用 yield 而不是 return 来提供对象时:
yield之前的代码在测试函数开始前执行。yield提供的值(例如fifo_agent)被传递给测试函数。测试函数执行。
测试函数执行完毕后,程序流程返回到 fixture 函数中,从
yield语句之后继续执行。这提供了一个执行“后处理”代码的机会。
以同步 FIFO 为例,读指针rptr和写指针wptr在达到最大值 15 之后,再次增加后值会变为 0。如果要对相关的覆盖组进行采样,可以让覆盖点的条件选为指针值为 0,与之相关的覆盖组定义为:
def get_cover_group_pointer_wraparound(is_wptr: int, agent: FIFOAgent) -> CovGroup:
# Define coverage conditions
def wraparound_ptr(bundle: InternalBundle):
return (bundle.wptr if is_wptr > 0 else bundle.rptr).value == 0
# Create coverage group
group = CovGroup("Pointer wraparound")
# Add coverage points
name = "Write ptr" if is_wptr > 0 else "Read ptr"
group.add_watch_point(agent.internal, {"event": wraparound_ptr}, name=f"{name} wraparound")
return group
在上面的代码中,我们可以通过控制is_wptr来实例化具有相同名字的覆盖组,但是里面的覆盖点分别对读、写指针进行采样。这两个点的结果最后都会合并到覆盖组Pointer wraparound中。
多个同名的
CovGroup对象的采样结果会在报告中合并,但其中同名覆盖点的 Bins 结构必须保持一致!
为了监测时序关系,我们可以定义一个异步函数wraparound_sequence,在一个无限循环中不断监测指针的值,当值达到 15 之后,再等待指针的结果变为 0 后进行采样,fixture 部分的完整代码为:
import toffee_test
from toffee import create_task, Value
@toffee_test.fixture
async def agent(toffee_request: toffee_test.ToffeeRequest):
fifo_dut: DUTSyncFIFO = toffee_request.create_dut(DUTSyncFIFO, "clk")
start_clock(fifo_dut)
read = ReadBundle().bind(fifo_dut)
write = WriteBundle().bind(fifo_dut)
internal = InternalBundle().from_prefix("SyncFIFO_").bind(fifo_dut)
fifo_agent = FIFOAgent(fifo_dut.rst_n, read, write, internal)
toffee_request.add_cov_groups([
get_cover_group_basic_operations(fifo_agent),
get_cover_group_fifo_state(fifo_agent),
get_cover_group_boundary_operations(fifo_agent),
get_cover_group_pointer_compare(fifo_agent)
])
# Custom sample group
cover_pointer_wraparound = [get_cover_group_pointer_wraparound(x, fifo_agent) for x in range(2)]
# Time sequences
async def wraparound_sequence(is_wptr: bool):
ptr = fifo_agent.internal.wptr if is_wptr else fifo_agent.internal.rptr
while True:
await Value(ptr, 0xf)
await Value(ptr, 0)
cover_pointer_wraparound[is_wptr].sample()
# Detecting sequence
create_task(wraparound_sequence(False))
create_task(wraparound_sequence(True))
yield fifo_agent
# 把 cover_pointer_wraparound 中的元素合并到 cov_groups 中
toffee_request.cov_groups.extend(cover_pointer_wraparound)
关于 create_task:
在上面的代码中,我们使用了 create_task(coroutine)。这是一个关键的异步编程工具,它的作用是:
接收一个协程对象(如
wraparound_sequence(True)的调用结果)。将这个协程安排到事件循环中,使其尽快开始执行,成为一个独立的后台任务。
create_task本身立即返回一个Task对象(可以用于后续管理,如取消任务、后续用await等待完成),而不会直接等待它所启动的协程执行完成。
这与 await coroutine 不同,await 会暂停当前流程直到被等待的协程完成。而 create_task 允许我们“发射”一个任务让它在后台运行,同时当前代码流可以继续执行其他事情。
通过 create_task,我们可以让多个验证逻辑片段真正地并发运行,互相协作,共同完成验证任务。
7.5 小结
功能覆盖率是衡量验证完备性的核心指标,它关注设计功能是否按预期被测试到。通过在 Toffee 中使用 CovGroup 和 add_watch_point 定义覆盖模型,结合周期性自动采样和基于特定序列的手动采样,我们可以有效地收集覆盖率数据,发现验证漏洞,并最终提高验证质量。
7.6 练习
本节的练习已经发布,请查阅【学习任务2: Toffee 部分】 4. 收集功能覆盖率。
8. 打包验证环境
随着验证环境变得复杂,我们需要一个更高层次的容器来管理它们。Env在 Toffee 中就扮演了这个角色。
它的主要职责包括:
实例化组件:在
Env内部实例化验证环境中所需的所有Agent组件。管理接口连接:负责确保每个
Agent都获得了正确的Bundle接口实例,Bundle通常代表了与待验证设计(DUT)交互的物理或逻辑接口。定义参考模型规范:
Env的结构(即其包含的Agent及其方法)隐式地定义了参考模型(Reference Model)需要遵循的接口规范。集成与同步参考模型:对于遵循规范编写的参考模型,
Env提供了附加(attach)机制,并负责在运行时自动将测试激励和监测数据同步给这些模型。
8.1 创建 Env
要定义一个具体的验证环境,你需要创建一个新的 Python 类,并让它继承自 Toffee 提供的 toffee.env.Env 基类。在你的自定义 Env 类中,通常会在其初始化方法 (__init__) 中完成 Agent 的实例化。
以下是一个简单的 Env 定义示例:
from toffee.env import *
class DualPortStackEnv(Env):
"""一个包含两个栈接口 Agent 的验证环境示例"""
def __init__(self, port1_bundle: StackPortBundle, port2_bundle: StackPortBundle):
# 调用父类的初始化方法
super().__init__()
# 在 Env 内部实例化所需的 Agent,并将 Bundle 传递给它们
# Agent 实例通常作为 Env 的属性,方便后续访问
self.port1_agent = StackAgent(port1_bundle)
self.port2_agent = StackAgent(port2_bundle)
在这个例子中:
我们定义了
DualPortStackEnv类,继承自Env。__init__方法接收两个Bundle对象作为参数。在
__init__内部,我们实例化了两个StackAgent,分别命名为port1_agent和port2_agent,并将对应的Bundle对象传递给了它们。这两个Agent现在成为了DualPortStackEnv实例的属性。
Bundle 的连接可以在 Env 外部完成,也可以在 Env 内部实现。关键在于确保每个 Agent 都接收到了正确的 Bundle 实例。
如果当前验证场景不需要编写参考模型进行行为比对,那么至此,验证环境的核心结构已经搭建完毕。可以直接编写测试用例,并在用例中使用 Env 实例及其包含的 Agent 提供的接口与待验证设计(DUT)进行交互,例如:
# 假设 StackPortBundle 和 DualPortStackEnv 已定义
port1_bundle = StackPortBundle()
port2_bundle = StackPortBundle()
env = DualPortStackEnv(port1_bundle, port2_bundle)
# 通过 Env 访问 Agent 的方法来驱动 DUT 或获取数据
await env.port1_agent.push(1)
await env.port2_agent.push(1)
print(await env.port1_agent.pop())
print(await env.port2_agent.pop())
8.2 绑定参考模型
如前所述,Env 的结构定义了其包含的所有 Agent 及其方法(包括驱动方法和监测方法),这构成了验证环境的外部接口。例如,对于上述 DualPortStackEnv,其接口结构可以表示为:
DualPortStackEnv
- port1_agent (类型: StackAgent)
- @driver_method push(data)
- @driver_method pop() -> value
- @monitor_method some_monitor() -> value
- port2_agent (类型: StackAgent)
- @driver_method push(data)
- @driver_method pop() -> value
- @monitor_method some_monitor() -> value
参考模型(Reference Model)的编写需要遵循这个由 Env 定义的接口规范。符合规范的参考模型可以使用 attach 方法附加到 Env 实例上。Env 负责将测试用例对 Agent 驱动方法的调用以及 Agent 监测方法获取的数据,自动同步给所有附加的参考模型。附加操作示例如下:
env = DualPortStackEnv(port1_bundle, port2_bundle)
env.attach(StackRefModel())
一个 Env 实例可以附加多个参考模型。所有附加的参考模型都会被 Env 自动管理和同步。参考模型的具体编写方法将在下一节详细介绍。
9. 编写参考模型
参考模型(Reference Model)在芯片验证中扮演着关键角色,它通常用于模拟待验证设计(DUT)的预期行为。在验证过程中,通过比较参考模型的输出与 DUT 的实际输出,可以判断 DUT 的功能是否正确
参考模型还有其他称呼,例如黄金模型(Golden model),预测器(Predictor)等。
在 Toffee 验证环境中,参考模型需要遵循其所附加的 Env 定义的接口规范。这样,Env 才能够自动地将驱动操作和监测数据同步给参考模型,实现自动化验证。
9.1 参考模型的实现方式
Toffee 框架为参考模型的实现提供了两种主要模式。开发者可以根据参考模型的复杂度、状态管理需求以及与 DUT 交互的时序特性来选择最合适的模式。这两种模式编写的模型均可通过 Env 的 attach 方法进行集成和自动同步。
函数调用模式:参考模型的行为由一系列响应特定事件(方法调用)的钩子函数来定义。框架在检测到匹配的事件时,自动调用这些钩子函数。
独立执行流模式:参考模型的行为被封装在一个或多个独立的、通常是异步的执行流程中(如
async def main)。模型在此流程中主动通过端口 等待并获取数据,控制自己的执行逻辑。
如何选择实现模式?
函数调用模式:
优点:实现相对简单直接,尤其适用于无状态或状态逻辑简单的模型。框架自动处理驱动方法返回值的比较,减少了样板代码。
缺点:对于具有复杂状态、需要精细控制内部时序或处理多接口间复杂依赖关系的模型,可能会变得难以管理。模型是被动响应事件的。
适用场景:简单的协议检查器、无状态的行为模型、主要关注点分离的多个小型模型等。
独立执行流模式:
优点:对模型内部状态和执行流程有完全的控制权,更适合模拟复杂的时序行为和状态机。模型可以主动管理数据流,处理接口间的复杂依赖。
缺点:需要编写更多的控制流和比对逻辑代码。需要理解异步编程(
async/await)。适用场景:复杂的总线功能模型(BFM)、需要模拟内部流水线或状态机的模型、需要精细控制事务处理流程的模型等。
差异总结:
接下来,我们将详细介绍如何编写这两种模式的参考模型。
9.2 使用函数调用模式
此模式的核心是定义钩子函数 (Hook Functions) 并使用 Toffee 提供的装饰器(@driver_hook, @monitor_hook, @agent_hook)将其与 Env 中 Agent 的特定方法关联起来。
假设 Env 接口如下:
StackEnv
- port_agent
- @driver_method push(data)
- @driver_method pop() -> value
- @monitor_method monitor_pop_data() -> item
驱动函数钩子 (@driver_hook)
该装饰器用于响应 Agent 的驱动方法 (@driver_method 标记的方法) 调用。
基本用法
使用 @driver_hook 装饰模型中的方法,需要通过 agent_name 和 driver_name 参数指定要匹配的 Agent 实例名和驱动方法名。
钩子函数的参数列表(除 self 外)必须与对应的驱动方法的参数列表一致。框架会自动比较钩子函数的返回值与驱动方法的实际返回值(如果驱动方法有返回值)。
下面为示例代码:
from toffee.model import *
class StackRefModel(Model):
def __init__(self):
super().__init__()
# 匹配 port_agent.push(data)
@driver_hook(agent_name="port_agent", driver_name="push")
def handle_push(self, data): # 钩子函数名可自定义
pass
# 匹配 port_agent.pop()
@driver_hook(agent_name="port_agent", driver_name="pop")
def handle_pop(self): # 钩子函数名可自定义
pass
便捷匹配方式
Toffee 提供了几种简化匹配声明的方式:
路径指定:使用点号
.连接agent_name和driver_name作为第一个参数。@driver_hook("port_agent.push") def handle_push(self, data): ...函数名匹配驱动名:如果钩子函数的名称与驱动方法的名称相同,可以省略
driver_name参数。@driver_hook(agent_name="port_agent") def push(self, data): # 函数名 'push' 匹配 driver_name='push' ...函数名同时匹配 Agent 与驱动名:函数名使用双下划线
__分隔agent_name和driver_name,此时@driver_hook()无需参数。@driver_hook() def port_agent__push(self, data): # 函数名匹配 agent_name='port_agent', driver_name='push' ...
监测钩子函数 (@monitor_hook)
该装饰器用于接收并处理 Agent 的监测方法 (@monitor_method 标记的方法) 返回的数据。
基本用法
使用 @monitor_hook 装饰模型中的方法,需要通过 agent_name 和 monitor_name 参数指定目标。
监测钩子函数除了 self 外,必须额外接收一个参数(通常命名为 item 或 value),该参数用于接收监测方法的返回值。开发者需要在此钩子函数体内实现对接收到的数据 (item) 的检查逻辑。
下面为示例代码:
class StackRefModel(Model):
# 匹配 port_agent.monitor_pop_data()
@monitor_hook(agent_name="port_agent", monitor_name="monitor_pop_data")
def monitor_pop_data(self, item): # item 是 monitor_pop_data 的返回值
pass
便捷匹配方法
@monitor_hook 支持与 @driver_hook 相同的所有便捷匹配方式(路径、函数名匹配 monitor_name、__ 约定)。
Agent 钩子(@agent_hook)
该装饰器提供一种机制,让一个钩子函数能够处理某个 Agent 下的所有(或指定的多个)驱动和监测方法的调用/数据。
基本用法
使用 @agent_hook 装饰模型方法,需要通过 agent_name 参数指定目标 Agent。
钩子函数通常需要接收 self、 name (被调用的方法名) 和 item (对驱动方法是参数字典或元组,对监测方法是返回值) 这三个参数。
下面为示例代码:
class StackRefModel(Model):
@agent_hook("port_agent") # 匹配 port_agent 下的所有方法
def port_agent(self, name, item):
print(f"Model: Agent 'port_agent' method '{name}' called/monitored.")
pass
便捷匹配与高级选项
省略
agent_name:当钩子函数名与Agent名称相同时,@agent_hook()无需参数。agents参数:使用列表匹配多个 Agent (agents=["agent1", "agent2"])。class StackRefModel(Model): @agent_hook(agents=["port_agent", "port_agent2"]) def port_agent(self, driver_name, args): passmethods参数:使用列表仅匹配指定的方法 (methods=["port_agent.push", "port_agent.pop", ...]),方法名需包含 Agent 路径。class StackRefModel(Model): @agent_hook(methods=["port_agent.push", "port_agent.pop", "port_agent2.monitor_pop_data"]) def port_agent(self, driver_name, args): pass
Hook 调用顺序
在同一个仿真时间点或事件触发点,如果多个 Hook 匹配了同一个事件,可以通过参数配置它们的执行顺序。
priority参数:用于所有类型的 Hook (@driver_hook,@monitor_hook,@agent_hook)。数值越小,优先级越高(越先执行)。默认情况下,@monitor_hook的优先级通常较高。@driver_hook("port_agent.push", priority=10) # 优先级较低 def push(self, data): ... @monitor_hook("port_agent.monitor_pop_data", priority=5) # 优先级较高 def monitor_pop_data(self, item): ...sche_order参数:仅用于@driver_hook以及@agent_hook处理驱动方法时。它决定了 Hook 函数相对于Env中实际Agent驱动方法 (@driver_method) 的执行顺序。sche_order="model_first"(默认值): Hook 函数在驱动方法之前执行。sche_order="dut_first": Hook 函数在驱动方法执行之后(通常是其完成后)执行。
@driver_hook("port_agent.push", sche_order="dut_first") def push(self, data): # 这个 hook 会在 env.port_agent.push() 实际驱动 DUT *之后* 执行 pass
9.3 使用独立执行流模式
此模式的核心是使用 Toffee 提供的 端口类(DriverPort, MonitorPort, AgentPort)在模型内部建立与 Env 接口的连接点,并通过一个或多个异步方法(通常是 async def main)来主动获取数据和执行模型逻辑。
定义端口
首先,需要在模型的 init 方法中,实例化所需的端口类,并将它们与 Env 中 Agent 的目标方法进行匹配。端口是模型与外部(即 Env 同步过来的驱动调用和监测数据)交互的接口。
基本用法:
DriverPort(agent_name, driver_name):用于匹配Env中的驱动方法 (@driver_method)。模型通过从此端口获取数据来得知驱动方法何时被调用及其参数。MonitorPort(agent_name, monitor_name):用于匹配Env中的监测方法 (@monitor_method)。模型通过从此端口获取数据来得知监测方法的返回值。AgentPort(agent_name):一个端口匹配指定Agent下的所有驱动和监测方法。
from toffee.model import Model
from toffee.model_port import DriverPort, MonitorPort, AgentPort
class StackRefModel(Model):
def __init__(self):
super().__init__()
# 示例:使用基本匹配方式定义端口
self.push_port = DriverPort(agent_name="port_agent", driver_name="push")
self.pop_port = DriverPort(agent_name="port_agent", driver_name="pop")
self.monitor_pop_data_port = MonitorPort(agent_name="port_agent", monitor_name="monitor_pop_data")
# 或者,可以只用一个 AgentPort 来处理该 agent 的所有交互
# self.port_agent = AgentPort(agent_name="port_agent")
便捷匹配方式
端口实例化同样支持便捷匹配规则,这些规则应用于实例变量名和构造函数参数:
- 路径指定:将方法的完整路径 (
agent_name.method_name) 作为第一个参数。
self.push_port = DriverPort("port_agent.push")
- 变量名匹配方法名:如果实例变量名与方法名(驱动或监测)相同,可省略
driver_name或monitor_name参数。
self.push = DriverPort(agent_name="port_agent") # 变量名 'push' 匹配 driver_name
self.monitor_pop_data = MonitorPort(agent_name="port_agent") # 变量名匹配 monitor_name
- 变量名同时匹配 Agent 与方法名:变量名使用双下划线
__分隔agent_name和方法名,此时端口类构造函数无需参数。
self.port_agent__push = DriverPort() # 变量名匹配 agent_name 和 driver_name
self.port_agent__monitor_pop_data = MonitorPort() # 变量名匹配 agent_name 和 monitor_name
- AgentPort 省略
agent_name:如果实例变量名与 Agent 名称相同。
self.port_agent = AgentPort() # 变量名 'port_agent' 匹配 agent_name
实现异步执行流
我们需要在模型中定义核心异步方法: async def main(self):。Toffee 框架会在模型被附加到 Env 后自动启动并运行这个 main 方法。
在 main 方法中,使用 await port_instance() 语法来等待并从端口获取数据。这个 await 操作会暂停当前执行流,直到对应的端口接收到数据为止。获取数据后,模型执行其内部逻辑,这通常包括更新内部状态和执行必要的验证比对。
class StackRefModel(Model):
async def main(self):
print("Model (Independent Flow): Starting main execution loop.")
while True:
# 1. 主动等待 push 操作的驱动数据
push_args = await self.push_port() # push_args 是参数字典或元组
# 2. 主动等待 pop 操作被调用 (通常不关心 pop 的参数)
# 注意: await pop_port() 只是同步了 pop 调用发生的时间点
await self.pop_port()
# 3. 主动等待 pop 操作对应的监测数据
monitored_item = await self.monitor_pop_data_port() # 这是实际的 DUT 输出
使用 AgentPort
如果选择使用 AgentPort 来统一处理一个 Agent 的所有交互,那么 await 操作会返回一个元组,其中包含被调用的方法路径(字符串)和相关数据 (item)。你需要在执行流中根据方法路径来分发处理逻辑。
class StackRefModelWithAgentPort(Model):
def __init__(self):
super().__init__()
# 使用 AgentPort,假设变量名 'port_agent' 匹配 agent_name
self.port_agent = AgentPort(agent_name="port_agent")
类似的,当变量名称与 Agent 名称相同时,可以省略 agent_name 参数:
self.port_agent = AgentPort()
同时,也可以使用 agents 参数来匹配多个 Agent,或使用 methods 参数来匹配多个驱动函数或监测函数。
使用了 AgentPort 之后,参考模型可以通过 await 关键字来等待 Env 中的驱动函数或监测函数的调用,其返回数据将会是包含了函数路径以及相关参数的元组。
9.4 练习
本节的练习已经发布,请查阅【学习任务2: Toffee 部分】 5. 编写参考模型并打包验证环境。
拓展阅读
协程相关
Python 文档中关于协程的部分:https://docs.python.org/zh-cn/3.11/library/asyncio-task.html
Python 异步编程 - 搞明白 async, await (继续解释 yield): https://www.bilibili.com/video/BV1zJ7mzdEc8
Pytest 相关
💡Pytest 本身的功能和生态非常强大,推荐阅读下面的内容:
pytest 中 fixture 的用法
pytest 中标记功能 mark 的用法
pytest 实现测试函数的参数化
利用多核并行,加快测试用例运行速度:pytest-xdist
⚠️警告:开启多核并行运行测试用例后,如果对比顺序运行测试用例的结果,发现覆盖率下降,说明顺序运行的一部分覆盖率是靠 DUT 初始状态的随机值给刷上去的,并非依赖输入激励的影响